오피니언
유전체 빅데이터 시대, 딥러닝(Deep Learning)의 진화
김태형 테라젠이텍스 이사
[김태형의 게놈이야기]축적되는 유전체 빅데이터 1%만 분석.."딥러닝으로 해결 가능"
1950년대 초 DNA 분자 구조가 최초로 밝혀지고 DNA가 유전정보가 담겨 있는 물리적 저장 장치라는 것을 알게 된 이후로 유전체 해독 기술은 비약적인 발전을 거듭해 새로운 게놈 시대를 이끌어냈다. 1975년 DNA를 처음으로 해독할 수 있게 된 이래 2007년 급속도로 발전한 NGS(차세대유전체해독) 기술 기반의 딥시퀀싱이 가능해졌으며 향후 5년 내 개개인의 30억 쌍의 DNA를 10만원(노바식, Novaseq)에 확보 가능할 것으로 기대를 모으고 있다.
이러한 기술을 기반으로 대규모 의료 데이터들이 생산됨에 따라 미국 국립보건원(NIH)은 이러한 데이터들을 체계적으로 모으기 위해 첫해인 2014년 한해에만 350억 원을, 나아가 2020년까지 총 연구비 약 7200억 원을 투자해 연구자들이 손쉽게 이 방대한 빅데이터를 접근할 수 있는 방법들을 찾겠다고 발표했다.
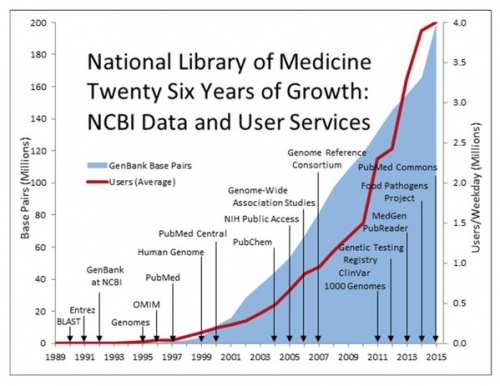
▲출처 : 미국 국립보건원(NIH)
2016년 기준으로 유전체 관련 정보를 보게 되면 NCBI의 유전형과 표현형 사이의 상호작용에 관한 연구 데이터 및 결과들을 제공하는 데이터베이스인 dbGaP에는 매년 20%씩 증가한 약 120만 명의 개인별 임상 정보와 유전체 데이터가 등록되었으며 약 700개의 연구가 진행중에 있다. GenBank에는 지구상 37만 종의 생명체의 2억 개의 유전체 서열이 등록되어 있는데 이 2억 개의 유전체 염기서열을 합치면 총합은 2.18 X 10의 20승 염기에 해당하는 어마어마한 데이터이다. 이러한 유전체 빅데이터를 관리하는 비용으로 NLM(National Library of Medi-cine)이 한해 사용되는 예산만 약 4000억 원 정도라고 한다. 또한 단일 유전체 데이터 생산으로 가장 큰 프로젝트로인 TCGA(The Cancer Genome Atlas)의 경우, 약 1조 원을 투자해 33개 암 종을 포함한 1만 1000명의 암환자들로부터 약 2.5 PB(페타바이트)의 유전체 데이터를 생산해 전 세계 암 연구자들이 사용할 수 있도록 제공하고 있다.
지난 2016년 10월 중순 캐나다 밴쿠버에서 열린 미국인간유전학회(ASHG)에 참석하여 최대 규모의 유전체 빅 데이터들(DiscovEHR, GnomAD, UK Biobank, 등)이 공개되는 현장에서 가슴 뛰었던 기억이 아직도 생생하다.
DiscovEHR의 경우는 가이징거 헬스 시스템 (Geisinger Health System)에 모여 있는 130만 명의 EHR 정보와 함께 25만 명의 WES 데이터를 생산하는 것으로 목표로 하고 있으며 현재(2017년 8월 기준) 약 9만 3000명에 육박한 환자들의 전장 엑솜 서열(WES)데이터를 확보한 상황이다.
브로드 연구소(Broad Institute)의 맥아써(MacArthur) 그룹의 노마드(GnomAD)는 사상 최대 규모인 약 14만 명(126,216 WES과 15,136 WGS)의 유전체 빅 데이터를 공개하기도 했으며 영국 바이오뱅크(UK Biobank)는 세계 최대 규모인 50만 명(40-69세)의 유전체 데이터를 공식적으로 연구자들에게 모두 오픈했다. 암, 심장질환, 뇌졸증, 당뇨병, 안과질환, 우울증, 관절염, 골다공증과 같은 다양한 질환에 해당하는 임상 정보 및 다양한 표현형 정보까지도 점차적으로 오픈할 것으로 예상 된다. 제노타입(Genotype), 임퓨테이션(imputation), 그리고 복제수변이(CNV) 데이터까지 포함하면 약 12TB 정도가 될 것으로 보이며 원시데이터(raw data)인 셀(CELL) 파일만 14TB이니 제대로 이러한 데이터를 다루기 위해서는 충분한 메모리와 최소 1PB 의 저장공간이 필요할 듯 하다.
이렇듯, 전 세계 생명과학 연구자들의 노력으로 유전형 데이터를 비롯해 암과 같은 특정 표현형에 이르기까지 다양한 수준의 생물학적 시스템을 측정하기 위한 대규모 데이터가 축적되었으며 특히 유전체, 전사체, 후성 유전체, 그리고 단백질체와 같은 오믹스 데이터들과 임상 정보를 구축한 데이터베이스들(GTEx, NCI-60, ENCODE, ICGC, 1000 Genome, NIH Epigenomics Project, GIANT)이 계속해서 공개되고 있다.
이는 곧 생명과학 연구자들에게 즉시 활용 가능한 다양한 연구 리소스를 제공해 매우 효율적인 실험 디자인 및 임상 유전체 분석에 적용될 수 있다.
하지만 제공되는 데이터에 비해 아직 활용 가능한 연구자들의 이해도가 부족하여 현재는 생명정보학자(Bioinformatist)에 국한해 이용하는 것이 현실이며 이는 전체 빅 데이터들이 쏟아지는 것과 별개로 정작 이 데이터를 잘 활용하는 것이 또 다른 문제임을 보여준다. 실제 애리조나 대학의 앤 바커(Ann Barker) 박사가 미국 암학회(AACR17)에서 발표하기를 전체 암 유전체 데이터 중 90%가 지난 2년 사이에 생산이 되었는데 그 데이터 중 단지 1%만이 분석이 완료되었다고 한다. 즉, 지금의 유전체 데이터 생산 속도를 사람의 분석능력으론 따라잡지 못한다는 것이다.
한 사람의 전체 유전체 데이터(WGS 30X)를 분석하기 위해서는 대략 5000 컴퓨팅 시간과 1TB의 컴퓨터 저장 공간이 필요하다고 한다. HLI(Human Longevity, Inc)의 엔터프라이즈 서비스 헤더인 '브라이언 쿤(Bryan Coon)'이 말하길 HLI는 원시 서열 데이터만 해도 매일 12TB (WGS 120 샘플, 100Gb/1 샘플) 이상을 생산하고 이를 효율적으로 처리하기 위해 AWS(Amazon Web Services)를 사용하고 있다고 발표를 하기도 했다. 실제 작년 한 해에만 전 세계적으로 100만 명의 전장 유전체 시퀀싱(WGS)데이터가 생산되어 실제 분석 데이터까지 포함하면 1000PB/년 정도로 전세계 병원에서 생산되는 이미징 데이터 생산(450PB/년)을 이미 앞섰다. 덧붙이자면 본인이 근무하고 있는 테라젠이텍스 바이오연구소에서도 매년 1 PB 이상을 증설하고 있다.
최근 유전체 빅 데이터의 활용도를 극대화 하기 위해 제안되는 것이 머신러닝의 일부 기술인 딥러닝이다. 이 딥러닝을 포함한 인공지능이란 개념은 1950년대에 앨런 튜링에 의해 처음 제안되었는데 아주 오랜 기간 동안 기술 발전의 정체기를 거쳐 최근 10년 사이 머신러닝 특히 딥러닝 기술과 GPU 기술의 괄목할 발전으로 인해 AI 관련 비즈니스가 급속도로 발전하게 되었다.
그리고 이러한 두 기술(유전체 빅데이터 & 인공지능)을 융합해 인류가 아직 해결하지 못한 복잡한 생명현상을 밝혀내는 일들을 해보려 하는 시도가 최근 이뤄지고 있다.
최근 머신러닝과 함께 급속히 발전하는 딥러닝 기술은 이미지인식, 음성 인식, 그리고 자연어 처리에 있어 인간 수준의 성능을 발휘하거나 이미 넘어서 이젠 생명의 메커니즘을 이해하기 위해 쌓여 있는 유전체 빅데이터를 처리하는 분야로 빠르게 진입하고 있다.
정리하면 전 세계 생명과학 연구자들의 노력으로 대규모 유전형 데이터에서부터 암과 같은 특정 표현형에 이르기 까지 다양한 수준의 생물학적 시스템을 측정하기 위한 대규모 유전체 빅데이터가 축적되어 가고 있고 이로 인해 최근 부상하는 데이터 처리 기술과 함께 게놈생물학, 게놈의학 그리고 정밀의학 분야가 몇 년 이내 더욱 급속히 성장할 것으로 예상된다.
참고문헌
- NIH invests almost $32 million to increas… : http://www.nih.gov/news/health/oct2014/od-09.htm
- Congressional Justification FY 2018 : https://www.nlm.nih.gov/about/2018CJ.html
- TCGA: https://cancergenome.nih.gov/abouttcga
- GnomAD: http://gnomad.broadinstitute.org/
- UK Biobank: http://www.ukbiobank.ac.uk/register-apply/
- M. K. Leung, A. Delong, B. Alipanahi, and B. J. Frey, “Machine learning in genomic medicine: A review of computational problems and data sets,” Proc. IEEE, vol. 104, no. 1, pp. 176–197, Jan. 2016.















